6 września 2022
Optyczne rozpoznawanie znaków w Safetica ONE
Spis treści:
- Wprowadzenie
- Jak działa OCR w Safetica ONE?
- W jaki sposób ustawić język OCR?
- Gdzie skonfigurować skanowanie OCR?
- Jak wybrać typy plików do OCR?
- Jak aktywować lub dezaktywować OCR dla określonej stacji roboczej?
- Co administrator widzi w logach?
- Przykład użycia
Wprowadzenie
Nowoczesna technologia OCR umożliwia wykrywanie poufnych danych w dokumentach PDF i plikach graficznych. Cały proces realizowany jest na poziomie stacji roboczej, dzięki czemu nie obciąża zasobów sieciowych, a także działa nawet w sytuacji gdy stacja jest w trybie offline. Zobacz w jaki sposób, krok po kroku, skonfigurować optyczne rozpoznawanie znaków by jeszcze lepiej chronić firmowe zasoby.
Jak działa OCR w Safetica ONE?
Funkcja OCR jest domyślnie wyłączona. Daje to administratorowi możliwość selektywnego kontrolowania obciążenia, jakie technologia OCR ma na punktach końcowych. Optyczne rozpoznawanie znaków obsługuje następujące typy obrazów: .png, .fit, .jpg, .jpeg, .jpe, .bmp. Można jednak wyodrębnić również obrazy innych formatów, takich jak .pdf, pliki prezentacji, ebooki i wiele innych.
Listę obsługiwanych formatów znajdziesz klikając tutaj.
Ze względu na wydajność Safetica skanuje tylko te pliki, które mają co najmniej 75% stron pokrytych obrazami. Strona pokryta obrazami musi zawierać obrazy na co najmniej 70% jej powierzchni.
W jaki sposób ustawić język OCR?
Ustawienia języka można znaleźć w Protection> Kategorie danych > Język OCR. Konfiguracja jest niezależna od języka Safetica Client skonfigurowanego dla punktów końcowych. Język OCR jest również scentralizowany i jednolity dla całego środowiska (nie można ustawić innego dla różnych punktów końcowych).

Możesz wybrać 2 różne języki do skanowania przez OCR, co może być przydatne w firmach pracujących w wielu językach. Jest to przydatne głównie dla różnych zestawów znaków, takich jak cyrylica, alfabet łaciński i chiński.
Ustawienie języka dodatkowego wpłynie jednak na wydajność stacji roboczej.
Języki bez znaków specjalnych stanowią podzbiór języków ze znakami specjalnymi. Oznacza to, że jeśli ustawisz np. czeski lub niemiecki jako język podstawowy, ustawienie angielskiego jako języka dodatkowego nie jest konieczne, ponieważ wszystkie znaki angielskiego są już zawarte w zestawach znaków czeskich/ niemieckich.
Gdzie skonfigurować skanowanie OCR?
Możesz skonfigurować ustawienia związane z inspekcją treści w Safetica Management Console > Protection> Kategorie danych. Wystarczy wybrać kategorię danych wrażliwych z listy po lewej stronie lub utworzyć nową i kliknąć przycisk Skonfiguruj kategorię danych.
Po włączeniu funkcji OCR w jednej kategorii danych zostanie ona aktywowana dla wszystkich typów plików określonych w tej kategorii danych.
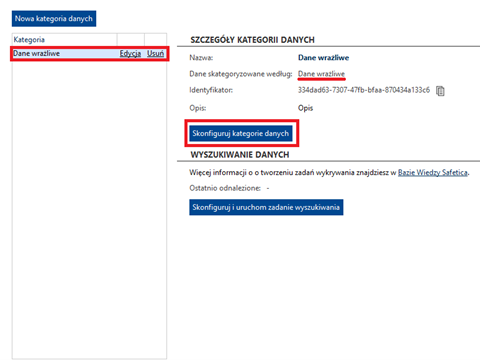
W kolejnym kroku zobaczysz nowe opcje dostępne w ramach konfiguracji reguły wykrywania: Optyczne rozpoznawanie znaków (OCR) i Rozszerzenia. Suwaki są od siebie niezależne.
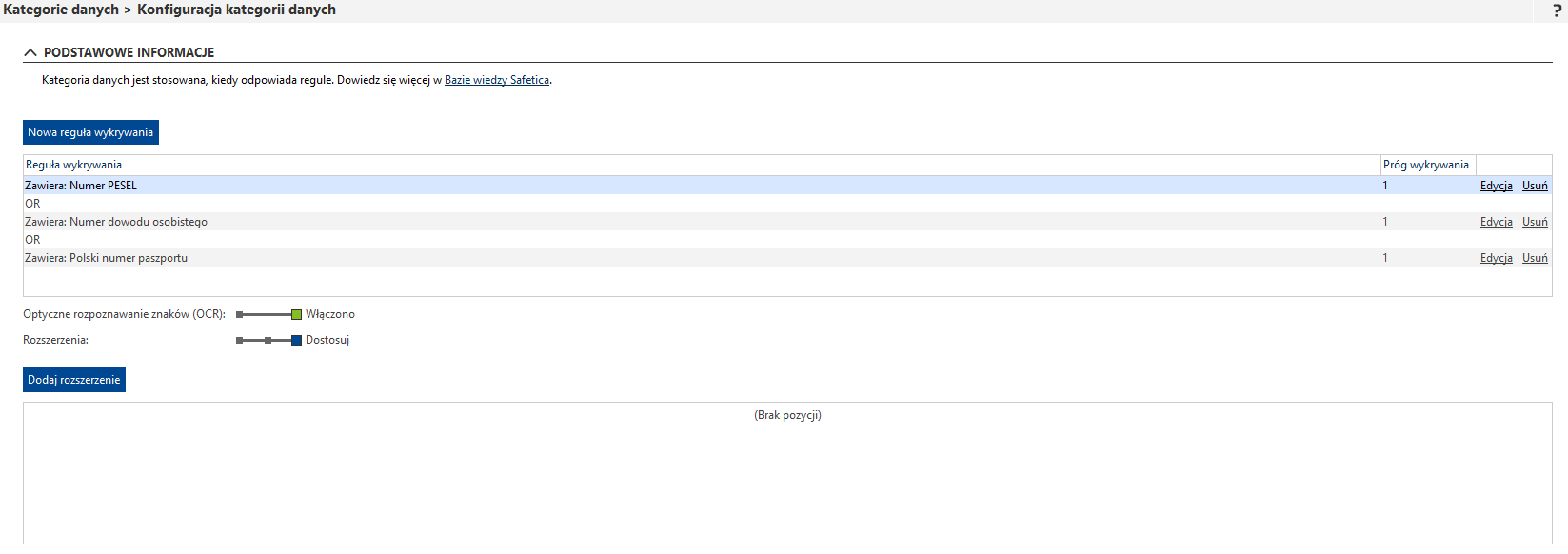
Jak wybrać typy plików do OCR?
Gdy funkcja OCR jest włączona, jest uruchamiana tylko dla formatów plików określonych w sekcji Rozszerzenia, a nie dla wszystkich plików.
Na przykład, jeśli administrator włączy funkcję OCR i następnie ustawi tylko rozszerzenie .pdf w sekcji Rozszerzenia, żadne inne formaty, nawet pliki obrazów .jpeg lub .bmp, nie zostaną przeskanowane za pomocą OCR. Jeśli administrator wybierze Zalecane w sekcji Rozszerzenia, OCR uruchomi skanowanie tylko dla zalecanych typów plików.
Jak aktywować lub dezaktywować OCR dla określonej stacji roboczej?
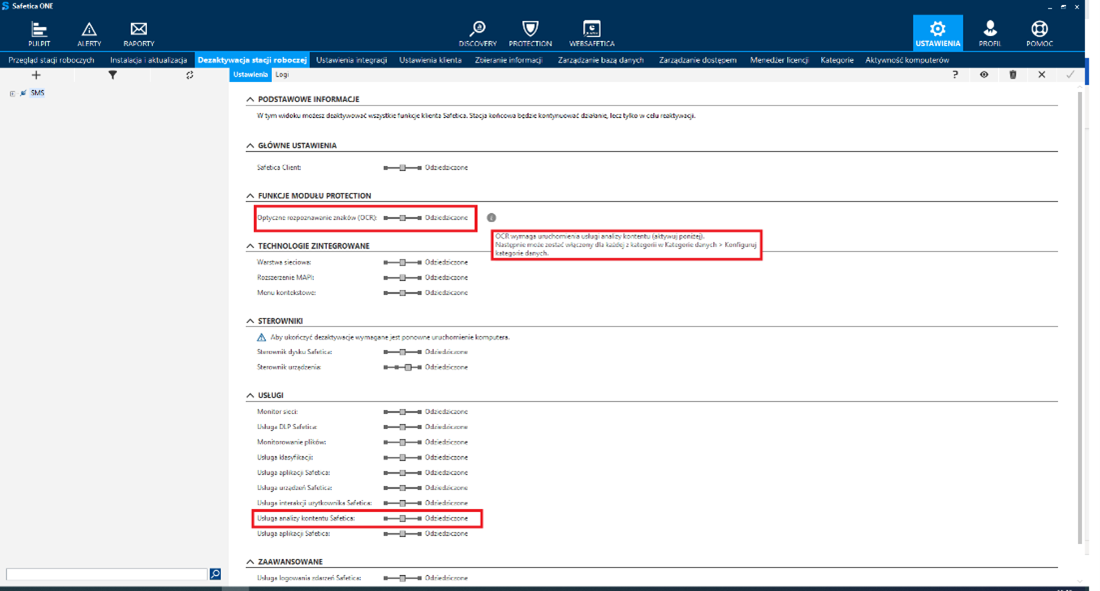
Przejdź do Ustawienia > Dezaktywacja stacji roboczej, wybierz konkretną stację lub grupę w drzewie użytkowników, a następnie w sekcji Funkcje modułu protection wybierz żądaną opcję za pomocą suwaka Optyczne rozpoznawanie znaków (OCR).
OCR jest zależny od usługi analizy kontentu Safetica. Jeśli dezaktywujesz usługę analizy treści, OCR nie zostanie uruchomiony, nawet jeśli aktywujesz ją w sekcji Funkcje protection.
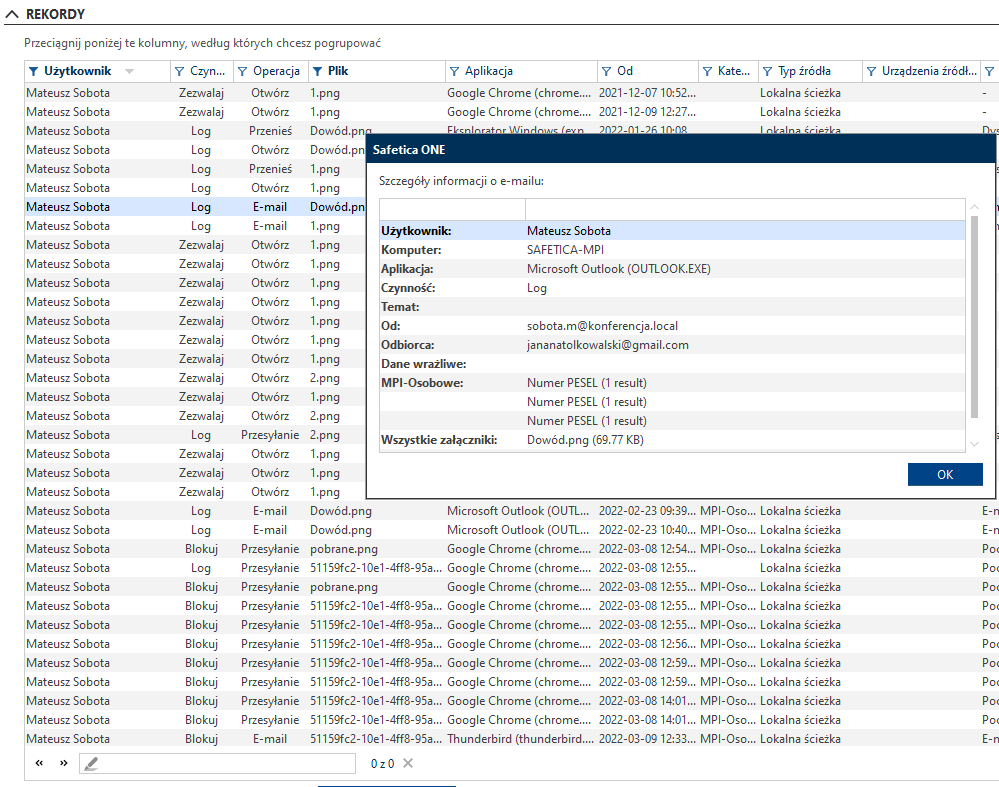
Co administrator widzi w logach?
Wyniki kontroli zawartości są widoczne w konsoli Safetica Management Console. Przejdź do Protection > Dzienniki DLP i kliknij Szczegóły w tabeli Rekordy.
Przykład użycia
Firma często używa plików .pdf, .docx, .pptx, .html i .xml. Administratorzy wiedzą jednak, że wrażliwe dane (numery kart kredytowych i IBAN) można znaleźć tylko w plikach .pdf i .docx.
Tworzą kategorię danych, która skanuje tylko pliki .pdf i .docx. To ustawienie całkowicie wyklucza typy plików graficznych ze skanowania OCR, więc firma nie będzie niepotrzebnie obciążać stacji roboczych.

Mateusz Piątek
senior product manager Safetica / Holm Security / Segura
Masz pytania?
Skontaktuj się ze mną:
piatek.m@dagma.pl
532 570 255
Skuteczna ochrona przed wyciekiem danych